I’ve been investigating this a bit more.
The hyphenation is done in src/System/Language/hyphenate.cpp. There are some commented out debugging statements in there that give some very useful information. If you uncomment those you can see on the terminal how the hyphenation patterns are loaded and how words are checked for their hyphenation.
So, what does this tell us? It seems that the tables are properly loaded:
TeXmacs] Loading hyphen.russian
.абр ==> .аб1р
.агро ==> .аг1ро
.ади ==> .ади2
.аи ==> .аи2
.акр ==> .ак1р
and so on.
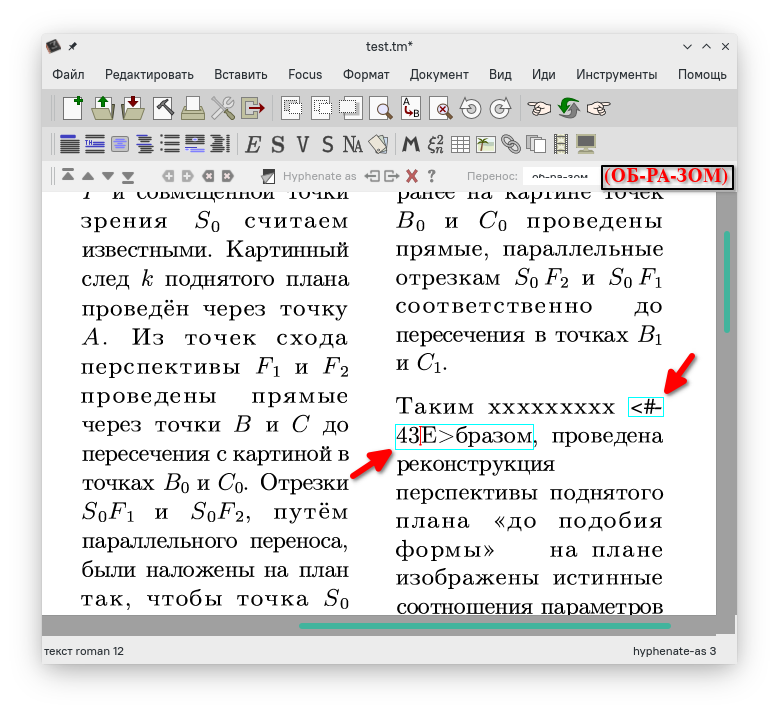
Now, let’s enter some text in Russian. The hyphenation algorithm prints unintelligible characters on the terminal:
.������������.
.������������. --> [ 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000, 100000000 ]
.������������.
and so on.
Let’s now try some words that are in the list of explicitly hyphenated words at the end of hyphen.russian:
понадоблюсь --> [ 100000000, 10000, 100000000, 10000, 100000000, 100000000, 10000, 100000000, 100000000, 100000000 ]
понадоблюсь --> [ 100000000, 10000, 100000000, 10000, 100000000, 100000000, 10000, 100000000, 100000000, 100000000 ]
понадоблюсь --> [ 100000000, 10000, 100000000, 10000, 100000000, 100000000, 10000, 100000000, 100000000, 100000000 ]
Hyphen <#43F><#43E><#43D><#430><#434><#43E><#431><#43B><#44E><#441><#44C>, 1
Yields <#43F><#43E>-, <#43D><#430><#434><#43E><#431><#43B><#44E><#441><#44C>
tada, all of a sudden we have intelligible characters and a successful hyphenation!
EDIT: And we’ve got the culprit, it’s the function locase_all in the line
s= "." * locase_all (s) * ".";
changing this to
s= "." * s * ".";
results in pattern hyphenation working:

So we’ll need to modify locase_all to work with Cyrillic characters.





 The cursor makes crazy jumps when moving through a hyphenated word. I’ll have to investigate further.
The cursor makes crazy jumps when moving through a hyphenated word. I’ll have to investigate further.